
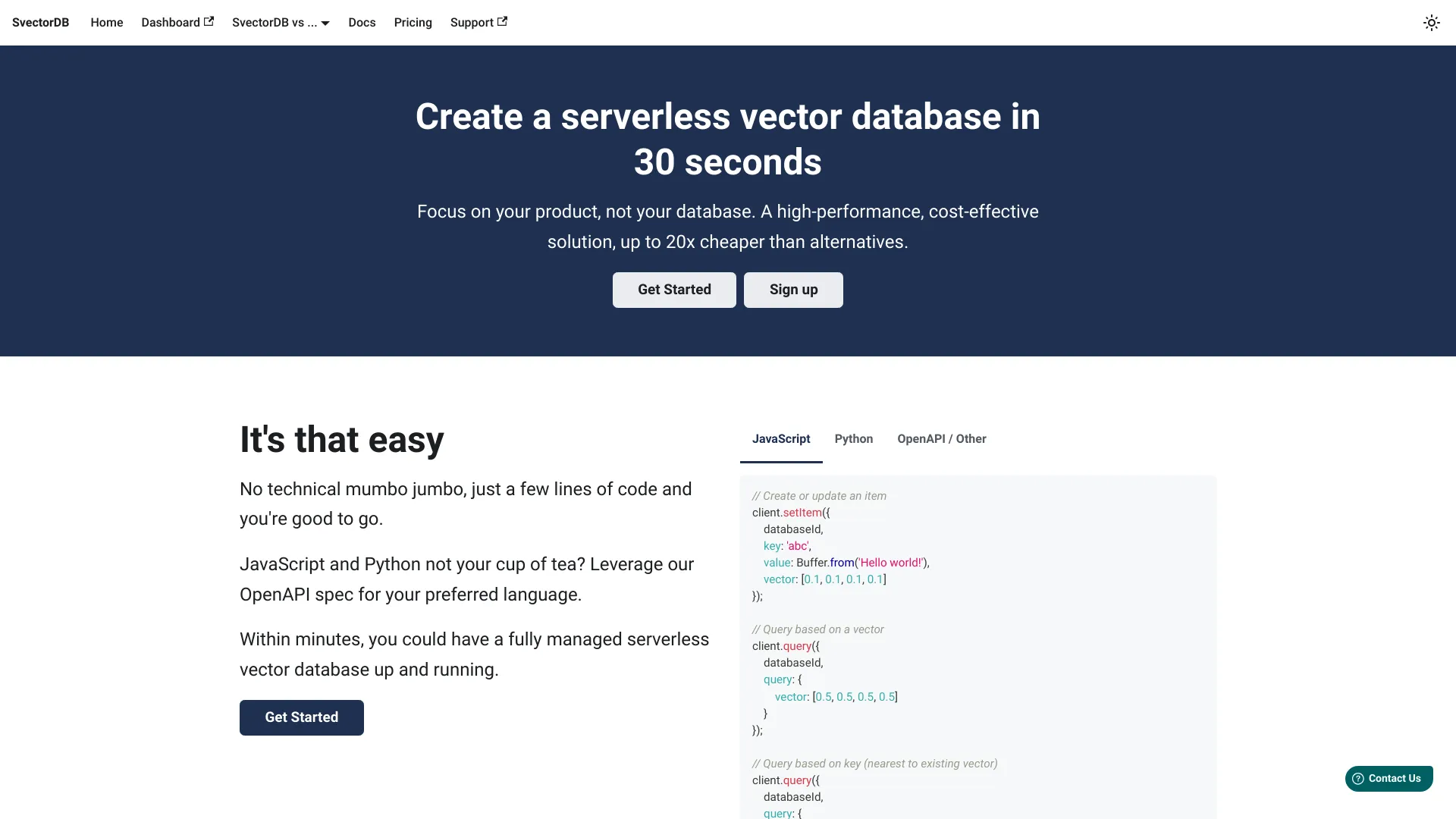
What is SvectorDB?
SvectorDB is a cutting-edge serverless vector database engineered specifically for AWS environments. This innovative solution provides developers and businesses with a cost-effective, high-performance platform for managing vector data. Designed to simplify vector data storage, querying, and analysis, SvectorDB eliminates the complexity and overhead of traditional database management systems. Its seamless AWS integration and robust performance make it an ideal choice for machine learning, natural language processing, and real-time analytics applications.
How to use SvectorDB?
Getting started with SvectorDB is straightforward. First, integrate the service with your existing AWS infrastructure through the AWS Management Console or API. Next, define your vector data schema and upload your datasets using the provided SDKs or REST APIs. The platform automatically handles scaling based on your workload requirements. You can then perform similarity searches, nearest neighbor queries, and vector analytics through intuitive query interfaces. Monitoring and management are simplified through comprehensive dashboards that provide real-time performance metrics and usage statistics.
Core features of SvectorDB?
SvectorDB offers several powerful features that distinguish it from traditional vector databases:
- Automatic scaling that dynamically adjusts resources based on query load and data volume
- Sub-millisecond latency for real-time vector search operations
- High throughput capability supporting millions of vector operations per second
- Native integration with AWS services including Lambda, SageMaker, and S3
- Simplified deployment with zero server management and minimal configuration
- Advanced indexing algorithms including HNSW and IVF-PQ for optimized performance
- Comprehensive security features with AWS IAM integration and encryption at rest and in transit