
ما هو SvectorDB?
SvectorDB هي قاعدة بيانات فيكتور بدون خادم متقدمة مصممة خصيصًا للبيئات الخاصة بـ AWS. هذا الحل الابتكاري يوفر للمطورين والشركات منصة فعالة من حيث التكلفة وأداءً عاليًا لإدارة بيانات الفيكتور. صممت لتسهيل تخزين بيانات الفيكتور، استعلامها، وتحليلها، تزيل SvectorDB تعقيدات وإضافات إدارة النظام التقليدية. بفضل دمجها السلس مع خدمات AWS وأدائها القوي، تعد SvectorDB خيارًا مثاليًا للتطبيقات في تعلم الآلة، معالجة اللغة الطبيعية، وتحليلات لحظية.
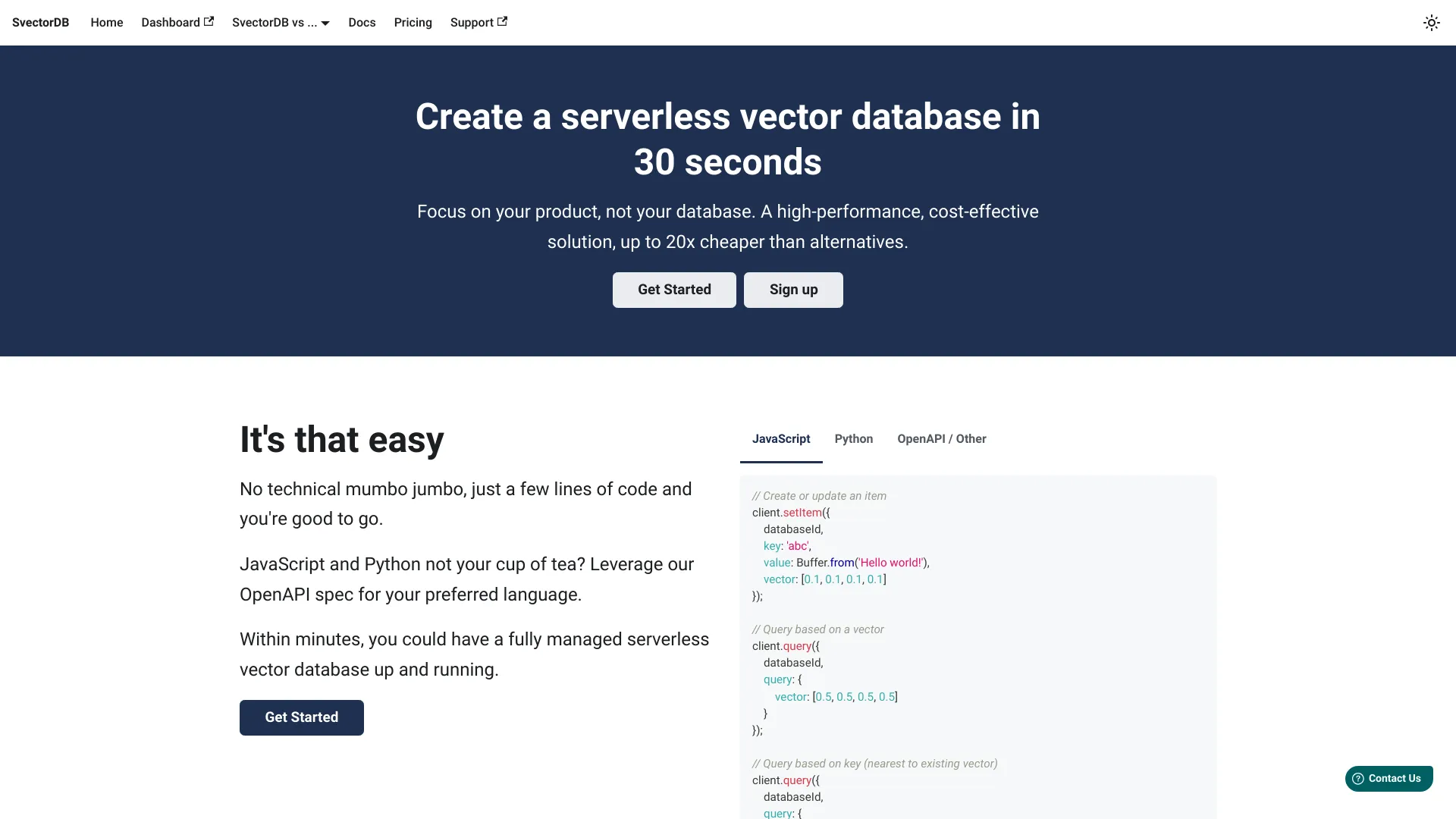
كيفية استخدام SvectorDB؟
يبدأ استخدام SvectorDB بسهولة. أولاً، قم بتكامل الخدمة مع بنية تحتية AWS الحالية الخاصة بك من خلال واجهة إدارة AWS أو API. ثم، قم بتحديد بنية بيانات الفيكتور الخاصة بك ورفع مجموعات البيانات الخاصة بك باستخدام SDKs أو REST APIs المقدمة. يتعامل النظام تلقائيًا مع التوسع بناءً على متطلبات عملك. بعد ذلك، يمكنك إجراء عمليات البحث المتشابهة، استعلامات جارب الأقرب، وتحليلات الفيكتور من خلال واجهات استعلام بديهية. يتم تبسيط المراقبة والإدارة من خلال لوحات تحكم شاملة توفر مؤشرات الأداء الحالية وبيانات الاستخدام.
ميزات رئيسية لـ SvectorDB؟
تقدم SvectorDB عدة ميزات قوية تتميز بها عن قواعد بيانات الفيكتور التقليدية:
- توسع تلقائي يضبط الموارد بشكل ديناميكي بناءً على زحزحة الاستعلامات وكمية البيانات
- تأخير منخفض تحت الميلي ثانية للعمليات البحثية الفيكتور لحظيًا
- قدرة عالية على التدفق تدعم الملايين من عمليات الفيكتور في الثانية
- دمج طبيعي مع خدمات AWS بما في ذلك Lambda، SageMaker، و S3
- تثبيت بسيط مع عدم الحاجة إلى إدارة الخادم والتعديل القليل
- خوارزميات تحسين متقدمة تشمل HNSW و IVF-PQ لأداء متميز
- ميزات أمان شاملة تتضمن دمج AWS IAM وتشفير في الاستقرار والتنقل