
SvectorDB는 무엇인가요?
SvectorDB는 AWS 환경용 특별히 설계된 최신 서버리스 벡터 데이터베이스입니다. 이 혁신적인 솔루션은 개발자와 기업이 벡터 데이터를 관리하는 비용 효율적이고 고성능 플랫폼을 제공합니다. 벡터 데이터 저장, 쿼리, 분석을 간소화하기 위해 설계된 SvectorDB는 전통적인 데이터베이스 관리 시스템의 복잡성과 부가 비용을 제거합니다. 원활한 AWS 통합과 강력한 성능으로, SvectorDB는 기계 학습, 자연어 처리, 실시간 분석 등의 응용 프로그램에 적합한 최적의 선택입니다.
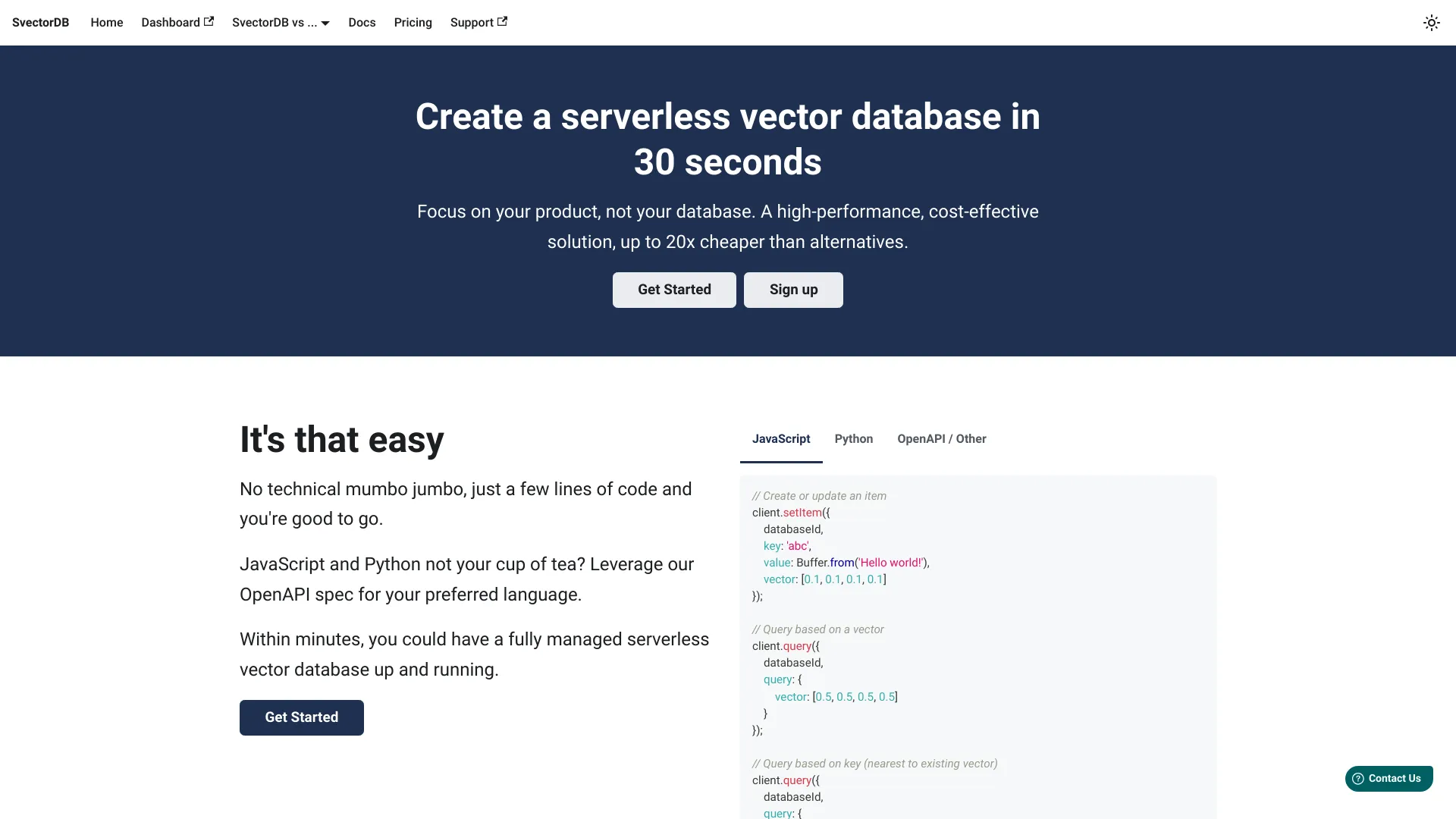
SvectorDB를 사용하는 방법?
SvectorDB를 시작하는 것은 간단합니다. 먼저, AWS Management Console 또는 API를 통해 기존 AWS 인프라와 서비스를 통합합니다. 다음으로, 제공된 SDK 또는 REST API를 사용하여 벡터 데이터 스키마를 정의하고 데이터 셋을 업로드합니다. 플랫폼은 작업 요구 사항에 따라 자동으로 확장을 처리합니다. 그런 다음, 유사도 검색, 가장 가까운 이웃 쿼리, 벡터 분석을 통한 인터페이스를 통해 수행할 수 있습니다. 모니터링과 관리는 실시간 성능 지표와 사용 통계를 제공하는 포괄적인 다이어그램을 통해 간소화됩니다.
SvectorDB의 핵심 기능?
SvectorDB는 전통적인 벡터 데이터베이스와 차별화되는 여러 강력한 기능을 제공합니다:
- 쿼리 부하와 데이터량에 따라 자동으로 자원을 조정하는 자동 확장
- 실시간 벡터 검색 작업에 대한 마이크로초 지연
- 초당 수백만 개의 벡터 작업을 지원하는 높은 토폴로지 능력
- Lambda, SageMaker, S3와 같은 AWS 서비스와의 원native 통합
- 서버 관리가 필요 없고 최소 설정으로 간소화된 배포
- 최적화된 성능을 위한 HNSW와 IVF-PQ와 같은 고급 인덱싱 알고리즘
- AWS IAM 통합과 휴식 중 및 전송 중 암호화를 포함한 포괄적인 보안 기능