
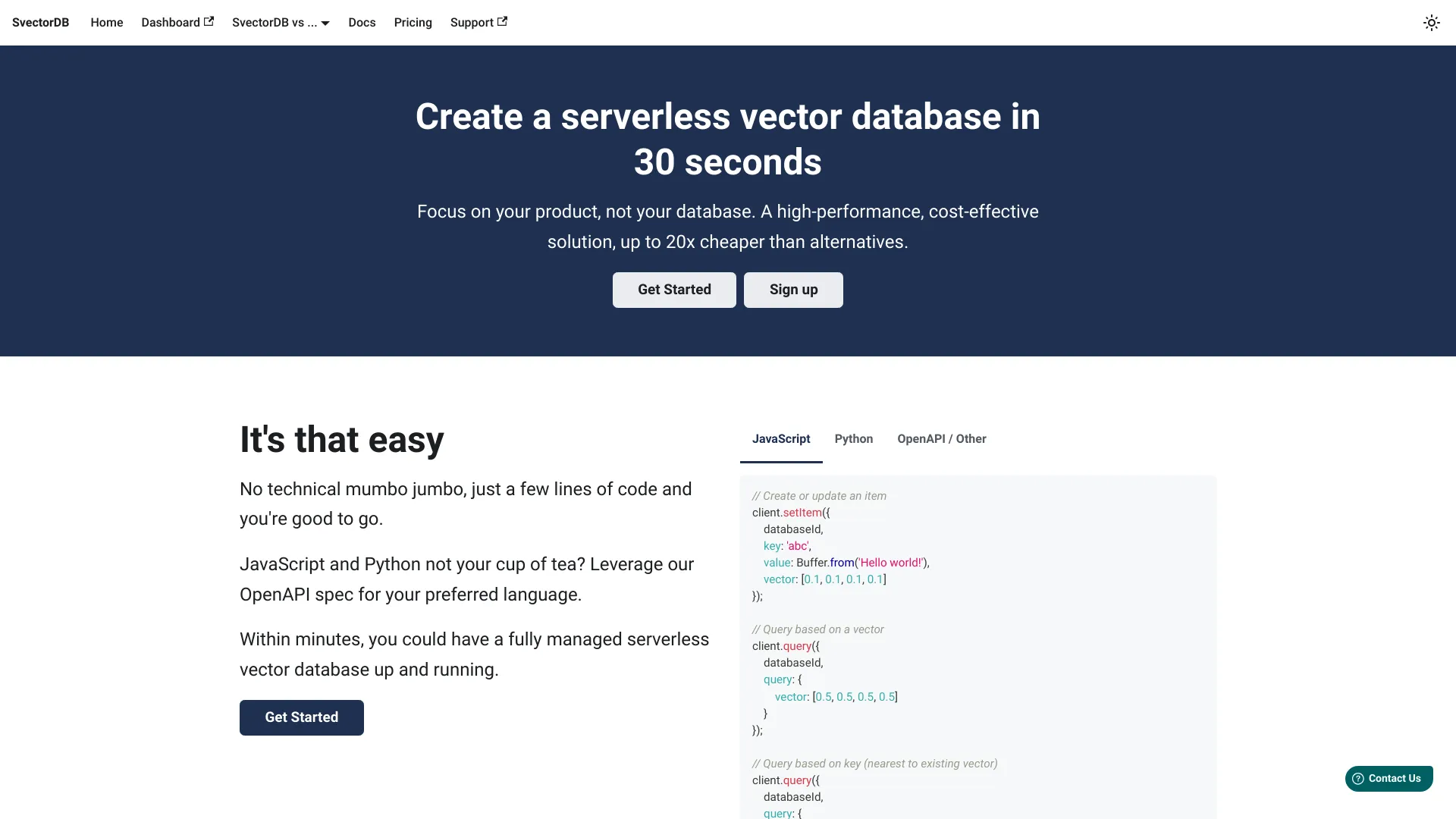
What is SvectorDB?
SvectorDB là một cơ sở dữ liệu vector không cần server tiên tiến được thiết kế đặc biệt cho môi trường AWS. Giải pháp này cung cấp cho các nhà phát triển và doanh nghiệp một nền tảng tiết kiệm chi phí và hiệu suất cao để quản lý dữ liệu vector. Được thiết kế để đơn giản hóa việc lưu trữ, truy vấn và phân tích dữ liệu vector, SvectorDB loại bỏ phức tạp và chi phí của hệ thống quản lý cơ sở dữ liệu truyền thống. Khả năng tích hợp mượt mà với các dịch vụ AWS và hiệu suất mạnh mẽ của nó làm cho nó trở thành lựa chọn lý tưởng cho các ứng dụng trong học máy, xử lý ngôn ngữ tự nhiên và phân tích thời gian thực.
How to use SvectorDB?
Bắt đầu với SvectorDB là rất đơn giản. Đầu tiên, tích hợp dịch vụ với cơ sở hạ tầng AWS hiện có của bạn thông qua AWS Management Console hoặc API. Tiếp theo, xác định cấu trúc dữ liệu vector của bạn và tải lên các tập dữ liệu của bạn bằng cách sử dụng SDK hoặc REST API được cung cấp. Plattform tự động xử lý mở rộng dựa trên yêu cầu công việc của bạn. Bạn có thể thực hiện các truy vấn tương tự, truy vấn hàng gần nhất và phân tích vector thông qua các giao diện truy vấn trực quan. Quản lý và theo dõi được đơn giản hóa thông qua các bảng điều khiển toàn diện cung cấp các chỉ số thời gian thực và thống kê sử dụng.
Core features of SvectorDB?
SvectorDB cung cấp một số tính năng mạnh mẽ giúp nó khác biệt so với các cơ sở dữ liệu vector truyền thống:
- Mở rộng tự động điều chỉnh tài nguyên động dựa trên tải truy vấn và thể tích dữ liệu
- Độ trễ dưới một micro giây cho các hoạt động tìm kiếm vector thời gian thực
- Khả năng lưu lượng cao hỗ trợ hàng triệu hoạt động vector mỗi giây
- Tích hợp bản địa với các dịch vụ AWS bao gồm Lambda, SageMaker và S3
- Triển khai đơn giản với việc quản lý server tối thiểu và cấu hình tối thiểu
- Các thuật toán chỉ mục tiên tiến bao gồm HNSW và IVF-PQ để tối ưu hóa hiệu suất
- Các tính năng bảo mật toàn diện với tích hợp AWS IAM và mã hóa khi nghỉ và trong quá trình truyền