
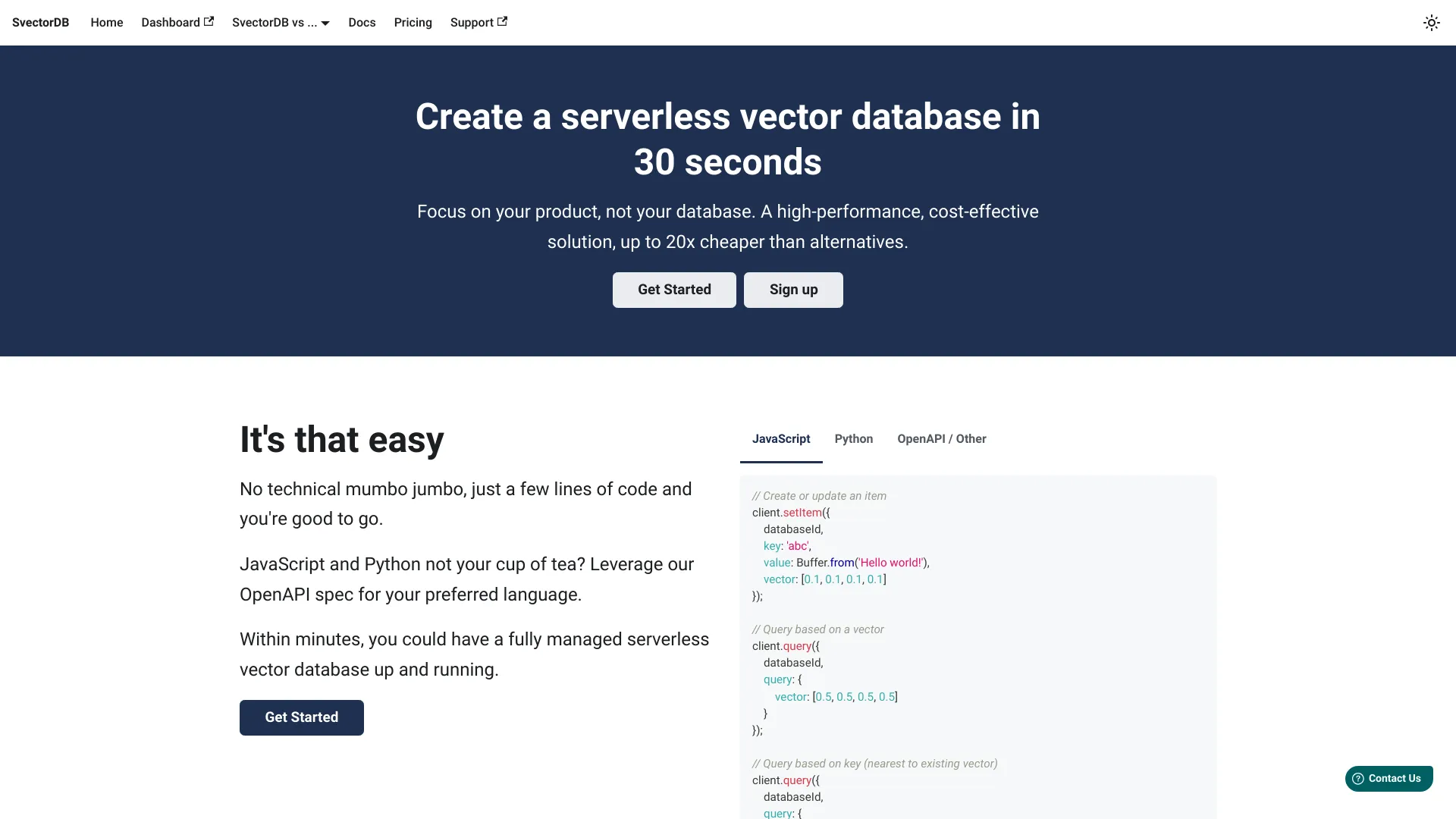
什么是 SvectorDB?
SvectorDB 是一款专为 AWS 环境设计的尖端无服务器向量数据库。这一创新解决方案为开发者和企业提供了一个成本效益高且性能卓越的平台,用于管理向量数据。SvectorDB 旨在简化向量数据的存储、查询和分析,消除了传统数据库管理系统的复杂性和开销。其与 AWS 服务的无缝集成和强大的性能使其成为机器学习、自然语言处理和实时分析应用的理想选择。
如何使用 SvectorDB?
开始使用 SvectorDB 非常简单。首先,通过 AWS 管理控制台或 API 将服务与现有的 AWS 基础设施集成。接下来,使用提供的 SDK 或 REST API 定义您的向量数据模式并上传数据集。平台会根据您的负载需求自动处理扩展。然后,您可以通过直观的查询接口执行相似度搜索、最近邻查询和向量分析。通过提供全面的仪表板简化了监控和管理,这些仪表板提供了实时性能指标和用量统计。
SvectorDB 的核心特性?
SvectorDB 提供了几个强大的特性,使其与传统向量数据库区别开来:
- 根据查询负载和数据量动态调整资源的自动扩展
- 实时向量搜索操作亚毫秒级延迟
- 支持每秒数百万次向量操作的高吞吐量能力
- 与 AWS 服务(包括 Lambda、SageMaker 和 S3)的本地集成
- 零服务器管理和最小配置的简化部署
- 包括 HNSW 和 IVF-PQ 在内的先进索引算法,以优化性能
- 完备的安全特性,包括 AWS IAM 集成和静态加密以及传输加密